I think you already have heard about data lakes. They used be called data directories. As you would expect, Data Rivers end up their “streams” in the lake. Here we go with data ponds:Connected Data Ponds: The Evolution of Data Lakes – HortonworksA lot has been said about Data Lakes over the past five years. The call to action from our industry to customers was to…hortonworks.com
Data ponds are subsets of data lakes that are separated for privacy (i.e. PII), governance, technology or costs.
Data droplets are the basic element. They describe information and dimensions about the subject. Here you can read more about these ontologies.
Then, we have data swamp. Larger organizations have this issue as a more severe one. The image below explains the differences:
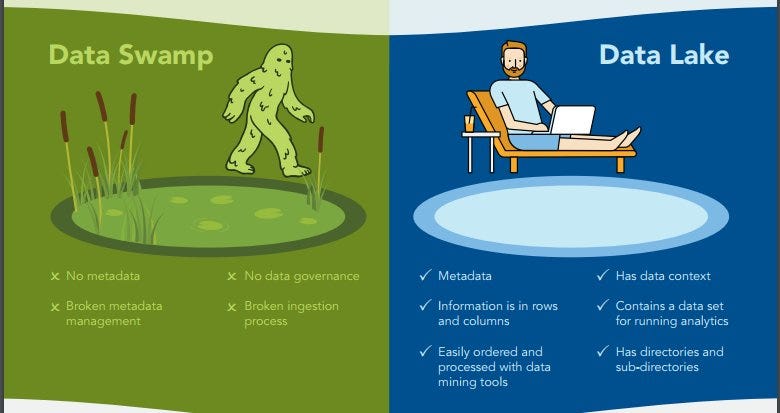
There are many reason behind a data swamp, below are a few:
- No policy for the metadata, definition, or the process
- Missing life-cycle for the data in the lake
- No stakeholder in the organization for the data
- Missing documentation about the preparation/usage process of the data
Bigger companies have started to find a solution for this issue. Metacat from Netflix help to understand the metadata in different services, or if you want to keep it simple with an user interface, CKAN data portal can help you manage and govern your data.
Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.
Commenter avatars come from Gravatar.